
 RSS 2.0 Blog feed
RSS 2.0 Blog feedThis is a reviewed version of an
original post published at Java.Net.
Recently there has been a renewed interest into the Actor programming model. The Actor
Model actually comes from the '70s, but as far as I'm aware it has been used only in a very limited subset
of industrial projects outside the area of telecoms. Erlang
(not by chance developed at Ericsson, a telecom industry), which is a language whose concurrency model is actor
oriented, is getting some attention but it's definitely a niche kind of a language. More interesting is the fact
that the Scala language developed its own actor-based platform, Akka, which is also
available to Java (and, generally speaking, to JVM-based languages). While there might (a-hum) be a lot of hype
about Scala and I'm pretty oriented to apply a big low-pass filter on trendy and cool stuff, actors have
definitely their place in the world when you're involved with complex concurrency. Once upon a time complex
concurrency was a matter only for specific industrial segments (e.g. the previously cited telecom industry), but
since things such as multi-cores and "the cloud" are invading our battlefields it's better to get prepared.
BTW, cloud and multi-core apart, I've already seen a lot of production code with scattered synchronized sections
that "perhaps shouldn't be there, but the thing works and it's better to let them stay". Note that this argument
is the typical smell of lack of testing, but concurrency is such a complex thing to test that even when the
customer is a good guy and achieves a very high coverage, often he can't be sure. The risk is to have some
unprotected section that sooner or later will lead to some inconsistency or raise an exception, up to the scary
possibility that a deadlock occurs. The better way to deal with concurrency is to pick a programming model that
avoids problems by costruction, and actors can be a good choice.
I've started doing some coding in the area and while I'm still far from a conclusion it's high time I posted some
considerations.
Actors and Akka
So, what are actors about? These are the basic principles:
- No shared (mutable) data. Each actor manages its own slice of data and there's nothing shared
with others. Thus no need for
synchronized. - Lightweight processes. Threads are still good, since they scale well; but, as per the previous point, they must be isolated.
- Communicate through Asynchronous Messages. What is traditionally done by invoking a method from an object to another now is done by sending an asynchronous message. The sender is never blocked, and the receiver gets all inbound messages enqueued into a 'mailbox', from which they will be consumed one at a time per each actor instance.
- Messages are immutable. This should be inferred by the previous points (otherwise bye bye "no shared mutable data"), but it's a good advice to stress the point.
With actors the contract of a computational entity is no more represented by an interface (that is an enumeration of methods) and behaviour, but by the set of messages that the actor can receive and send, and behaviour. Copying the first example in the Java API for Akka, a simple actor can be:
import akka.actor.UntypedActor;
import akka.event.EventHandler;
public class SampleUntypedActor extends UntypedActor
{
public void onReceive (Object message) throws Exception
{
if (message instanceof String)
{
getContext().replyUnsafe("Hello " + message);
}
else
{
throw new IllegalArgumentException("Unknown message: " + message);
}
}
}
Actors, being managed objects (and possibly distributed on a network), can't be directly accessed, but must be handled by references. For instance, to send a message to the previous actor:
import static akka.actor.Actors.*;
final ActorRef myActor = actorOf(SampleUntypedActor.class);
actor.start();
...
actor.tell("world");
Now Akka has a considerable value in being tested and optimized - performance is one of the reasons for which you
might want to use actors and it's not easy to achieve and Akka is known to scale to impressive numbers. But while
messages can be delivered in different fashions, unfortunately Akka seems not to be supporting publish &
subscribe which is my preferred way to go (I've seen references to extensions and possibly this feature could be
introduced in future). This is a first showstopper for me. Furthermore, basic concepts are simple but, as it
unfortunately often occurs, things get more complicated as you start digging into details. Also, you note the
total lack of syntactic sugar, as the incoming message is a vanilla Object and you need a cascade of
if (message instanceof ...) to deal with multiple messages. At least, for the things Akka calls
untyped actors: there are typed actors too, which can be even defined again by an interface to mimic method
calling, that Akka will manipulate through AOP to transform method invocation in message passing. An approach that
I don't like, because I think that in a message-passing software the approach must be evident in source code, not
masked under something that pretend to be method invocation; furthermore, method invocation semantics are
incompatible with publish & subscribe. So, I'd say that with Akka either you have no sugar or you're going to
sink into honey.
Anyway, just before publishing this blog post, I've learned that Akka
2.0 is going to have publish & subscribe. Excellent news. In the meantime?
Understanding what I want
In the meantime, I've started sketching some code on my own, to understand how I'd like to use actors. The idea is to learn things and then try to converge to Akka, eventually with a thin layer of syntactic sugar. There's enough work so far that's worth while a blog post, both for my personal need of writing down things and to discuss with others.
Since things must be given a real context I've started thinking of desktop applications, in particular two simple tools that I need: SolidBlue computes the fingerprint of the files contained in a directory (I use it for periodically checking the sanity of my photos and related backups) and blueShades provides a GUI for Argyll, a tool for color management, suited to my needs. Both are being implemented with the NetBeans Platform.
So let's focus on SolidBlue and its main feature. The scenario is:
- You select a directory.
- The application scans the directory recursively.
- For each discovered file, contents are loaded and the MD5 fingerprint is computed.
- Each MD5 computed fingerprint is stored into a flat file.
- A UI monitors the workflow displaying the current status on the screen.
The flow can be parallelised. For instance, directory recursive inspection can be performed by multiple threads, as well as the MD5 computation, which only involves the CPU. On the other hand, loading from the disk is something that it's better to serialize (that is, reading only one file at a time) in order to maximize the disk throughput (which it's the true bottleneck of the application). Indeed, things are a bit more complex than I've just said, but I'll be back on the issue later.
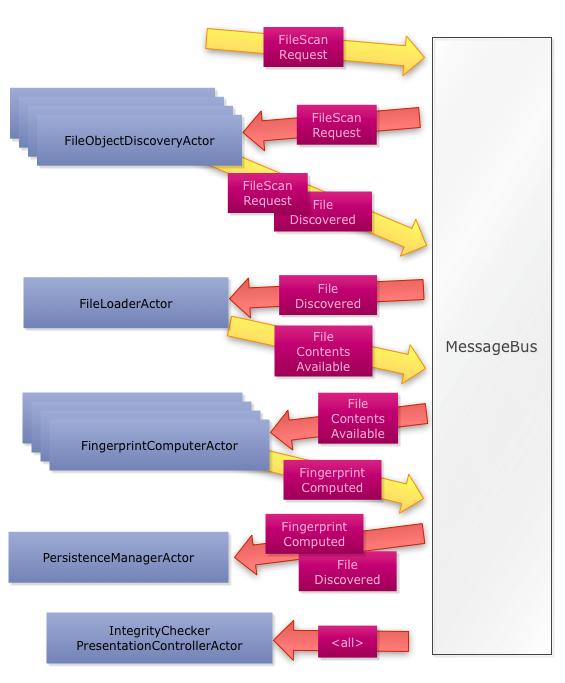
Actors in SolidBlue
Note: in the following code samples, I'm making use of Lombok annotations for some plumbing. This is not only great for everyday's work, but it also makes code samples much easier to read. Also, I'm only listing significant import statements, as well as skipping some non relevant code chunks.
Everything starts by sending to the system a message asking for a scan:
FileScanRequestMessage.forFolder("/Volume/Media/Photos")
.withFilter(withExtensions("NEF", "JPG", "TIF"))
.send();
As you can see, there's no target actor, but according to the "publish and subscribe" approach the message just
sends itself. The listing for FileScanRequestMessage is below:
package it.tidalwave.integritychecker;
import it.tidalwave.actor.MessageSupport;
import it.tidalwave.actor.annotation.Message;
@Message @Immutable @RequiredArgsConstructor(access=PRIVATE) @EqualsAndHashCode @ToString(callSuper=false)
public class FileScanRequestMessage extends MessageSupport
{
public static interface Filter
{
public boolean accepts (@Nonnull FileObject fileObject);
}
@Nonnull @Getter
private final FileObject folder;
@Nonnull @Getter
private final Filter filter;
@Nonnull
public static FileScanRequestMessage forFolder (final @Nonnull FileObject fileObject)
{
return new FileScanRequestMessage(fileObject, Filter.ANY);
}
@Nonnull
public FileScanRequestMessage withFilter (final @Nonnull Filter filter)
{
return new FileScanRequestMessage(folder, filter);
}
}
Somewhere there's a FileObjectDiscoveryActor that listens to that message:
package it.tidalwave.integritychecker.impl;
import it.tidalwave.actor.annotation.Actor;
import it.tidalwave.actor.annotation.ListensTo;
@Actor @ThreadSafe
public class FileObjectDiscoveryActor
{
public void onScanRequested (final @ListensTo FileScanRequestMessage message)
{
for (final FileObject child : message.getFolder().getChildren())
{
if (message.getFilter().accepts(child))
{
(child.isFolder() ? FileScanRequestMessage.forFile(child).withFilter(message.getFilter())
: FileDiscoveredMessage.forFile(child)).send();
}
}
}
}
You can see here my syntactic sugar: the actor is a POJO and methods designated to receive messages are annotated
by @ListensTo. Multiple methods can listen to multiple messages. The annotation is similar to @Observes
by CDI (JSR-299) - actually I'd love to reuse it, but it seems to have different semantics (e.g. by default it can
activate managed objects that are the target of an inbound message; furthermore there are multiple delivery
options related to transactionality that at the moment I'm not interested into).
Recursive directory navigation is implemented by sending another FileScanRequestMessage. When a
regular file is detected, a FileDiscoveredMessage is fired (there's no need to see its listing, as
it's straightforward).
Inbound messages are first enqueued and then dispatched in a FIFO fashion (with exceptions explained later). If
the actor is not thread safe, there's the guarantee that it can be engaged by a single thread at any time (thus,
messages are processed one per time). In this way there's no need to have synchronized sections. If the actor is
thread safe (the default), as FileDiscoveredMessage that's even stateless, it can be engaged by
multiple threads at the same time. The thread safety property is specified as an attribute of @Actor
(unfortunately @ThreadSafe can't help since its retention is compile time).
The second actor is the one that reads data from files:
package it.tidalwave.integritychecker.impl;
import it.tidalwave.actor.annotation.Actor;
import it.tidalwave.actor.annotation.ListensTo;
@Actor(initialPriority=Thread.MAX_PRIORITY) @ThreadSafe
public class FileLoaderActor
{
public void onFileDiscovered (final @ListensTo FileDiscoveredMessage message)
{
final FileObject fileObject = message.getFileObject();
try
{
final File file = FileUtil.toFile(fileObject);
final @Cleanup RandomAccessFile randomAccessFile = new RandomAccessFile(file, "r");
final MappedByteBuffer byteBuffer = randomAccessFile.getChannel().map(READ_ONLY, 0, file.length());
byteBuffer.load();
randomAccessFile.close();
new FileContentsAvailableMessage(fileObject, byteBuffer).send();
}
catch (Exception e)
{
FileDamageDetectedMessage.forFile(fileObject).withCause(e).send();
}
}
}
It uses memory-mapped I/O for speed and fires a FileContentsAvailableMessage carrying the bytes, or
a FileDamageDetectedMessage in case of error.
The next stage is the actor that computes the fingerprint:
package it.tidalwave.integritychecker.impl;
import it.tidalwave.actor.annotation.Actor;
import it.tidalwave.actor.annotation.ListensTo;
@Actor @ThreadSafe
public class FingerprintComputerActor
{
public void onFileContentsAvailable (final @ListensTo FileContentsAvailableMessage message)
throws NoSuchAlgorithmException
{
final String algorithm = "MD5";
final MessageDigest digestComputer = MessageDigest.getInstance(algorithm);
digestComputer.update(message.getContents());
final Fingerprint fingerprint = new Fingerprint(algorithm, toString(digestComputer.digest()));
FingerprintComputedMessage.forFile(message.getFileObject()).withFingerprint(fingerprint).send();
}
}
Again, a FingerprintComputedMessage message carrying the result is fired. The last stage is the
persistence actor:
package it.tidalwave.integritychecker.impl;
import it.tidalwave.actor.CollaborationStartedMessage;
import it.tidalwave.actor.MessageSupport;
import it.tidalwave.actor.annotation.Actor;
import it.tidalwave.actor.annotation.ListensTo;
import it.tidalwave.actor.annotation.Message;
import it.tidalwave.actor.annotation.OriginatedBy;
@Actor(threadSafe=false) @NotThreadSafe
public class PersistenceManagerActor
{
@Message(outOfBand=true) @ToString
static class FlushRequestMessage extends MessageSupport
{
}
private final Map<String, Object> map = new TreeMap<String, Object>();
private File persistenceFile;
private boolean flushPending;
public void onScanStarted (final @ListensTo CollaborationStartedMessage cMessage,
final @OriginatedBy FileScanRequestMessage message)
{
final File folder = FileUtil.toFile(message.getFolder());
final String fileName = new SimpleDateFormat("'fingerprints-'yyyyMMdd_HHmm'.txt'").format(new Date());
persistenceFile = new File(folder, fileName);
map.clear();
}
public void onFileDiscovered (final @ListensTo FileDiscoveredMessage message)
{
final String name = message.getFileObject().getNameExt();
if (!map.containsKey(name)) // message sequentiality is not guaranteed
{
map.put(name, "unavailable");
requestFlush();
}
}
public void onFingerprintComputed (final @ListensTo FingerprintComputedMessage message)
{
final String name = message.getFileObject().getNameExt();
final Fingerprint fingerprint = message.getFingerprint();
map.put(name, fingerprint);
requestFlush();
}
private void onFlushRequested (final @ListensTo FlushRequestMessage message)
throws InterruptedException, IOException
{
flushPending = false;
// writes data to file
}
private void requestFlush()
{
if (!flushPending)
{
new FlushRequestMessage().sendLater(5, TimeUnit.SECONDS);
flushPending = true;
}
}
}
The basic idea is not to write to disk every piece of data as it's generated, since it might be expensive (well,
perhaps writing to a relational database wouldn't be, but for a simple tool such as SolidBlue it makes more sense
to write to a flat file). So, data are first put into an in-memory map (a record is generated as soon as a file
has been discovered and later overwritten with the final result) that is periodically flushed to disk. So, the
actor is stateful, hence it's not thread safe (there must be only one instance). Whenever the map is changed, it's
marked 'dirty' and a request to flush it to the disk is generated. The flush will happen within 5 seconds, but
it's not a good idea to use a Java Timer as I'd run into the threading problems that I want to avoid. Instead, a
private FlushRequestMessage is sent back to itself with some delay, triggering the write to the
disk. This message is annotated as 'out-of-band', it means that must delivered with high priority (in practice,
it's placed at the head of the incoming message queue rather than the tail). Since the runtime guarantees that
only a single message can be processed by any actor instance at any time, there's no need to protect the map, or
the flushPending flag, by synchronized sections.
The onScanStarted() method is interesting, because it introduces the concept of collaborations.
Collaborations
Actually, asynchronicity is excellent for massively concurrent system (as well as, not to say, to model things that are asynchronous in nature, and there are many). But it's nice to know, in some way, that a sequence of things that happened in response to a message of yours has been completed. In my code I've called this concept “Collaboration”:
- Any message is always part of a Collaboration.
- If the thread creating a certain message is not bound to a Collaboration, a new Collaboration is created and the message will be considered its originator.
- The originator message will be delivered in threads bound to its Collaboration. This means that any further message, created as a consequence of the reception of the originator message, will share its Collaboration.
- A Collaboration keeps tracks of all the related messages and threads by means of reference counting.
- When there are no more pending messages or working threads for a Collaboration, it is considered completed.
Two special messages, CollaborationStartedMessage and CollaborationTerminatedMessage,
are fired by the runtime to notify of the creation and completion of collaborations.
When a message is sent, you can get its Collaboration object:
final Collaboration collaboration = new MyMessage().send();
and any listening method can get the Collaboration as well:
public void onMyMessage (final @ListensTo MyMessage message)
{
final Collaboration collaboration = message.getCollaboration();
...
}
By construction, thus, a Collaboration is attached to all the threads that are directly or
indirectly triggered by the originating message. This could be used for managing regular transactions (for
instance, attaching a javax.transaction.UserTransaction to the Collaboration). But
actors seem to be better dealing with Software Transactional Memory, so I drop this argument for now.
It's even possible to synchronously waiting for a Collaboration to complete:
collaboration.waitForCompletion();
even though I think it's only useful for tests. More interesting is the case in which a Collaboration
includes bidirectional interactions with a user: for instance, making a dialog box to pop up and wait for a
selection. In these circumstances, a Collaboration can be suspended (this means it is not considered
to be terminated even though there are no pending messages or working threads) and later resumed. More details in
a further post.
Collaborations is something that I don't expect to find in platforms such as Akka, since I'm not sure it's
feasible to have them working in an efficient way in a distributed context (I mean: maybe yes, maybe not, I
haven't studied the problem yet). But they are a nice feature to have if possible and perhaps it's possible to
implement it on top of an existing actor platform.
Back to the method onScanStarted(), it is clear now that it listens to the CollaborationStartedMessage
messages originated by a FileScanRequestMessage to initialize the storage of the fingerprints, which
must be located in the top scanned directory.
In a similar way, the IntegrityCheckerPresentationControllerActor listens to the various messages
being delivered, including those notifying the beginning and the end of the Collaboration, to update
the user interface:
package it.tidalwave.integritychecker.ui.impl;
import it.tidalwave.actor.MessageSupport;
import it.tidalwave.actor.Collaboration;
import it.tidalwave.actor.CollaborationCompletedMessage;
import it.tidalwave.actor.CollaborationStartedMessage;
import it.tidalwave.actor.annotation.Actor;
import it.tidalwave.actor.annotation.ListensTo;
import it.tidalwave.actor.annotation.Message;
import it.tidalwave.actor.annotation.OriginatedBy;
@Actor(threadSafe=false) @NotThreadSafe
public class IntegrityCheckerPresentationControllerActor
{
private static final double K10 = 1000;
private static final double M10 = 1000000;
@Message(outOfBand=true, daemon=true) @ToString
private static class RefreshPresentationMessage extends MessageSupport
{
}
private final IntegrityCheckerPresentationBuilder presentationBuilder = Locator.find(IntegrityCheckerPresentationBuilder.class);
private final IntegrityCheckerPresentation presentation = presentationBuilder.createPresentation();
private final Statistics statistics = new Statistics();
private boolean refreshing = false;
private int totalFileCount;
private long totalDataSize;
private int processedFileCount;
private long processedDataSize;
public void onScanStarted (final @ListensTo CollaborationStartedMessage cMessage,
final @OriginatedBy FileScanRequestMessage message)
{
totalFileCount = 0;
totalDataSize = 0;
processedFileCount = 0;
processedDataSize = 0;
refreshing = true;
new RefreshPresentationMessage().send();
}
public void onScanCompleted (final @ListensTo CollaborationCompletedMessage cMessage,
final @OriginatedBy FileScanRequestMessage message)
{
refreshing = false;
presentation.setProgressLabel("done");
new RefreshPresentationMessage().send();
}
public void onFileDiscovered (final @ListensTo FileDiscoveredMessage message)
{
totalFileCount++;
totalDataSize += message.getFileObject().getSize();
}
public void onFingerprintComputed (final @ListensTo FingerprintComputedMessage message)
{
processedFileCount++;
processedDataSize += message.getFileObject().getSize();
final Collaboration collaboration = message.getCollaboration();
final long elapsedTime = collaboration.getDuration().getMillis();
final double speed = (processedDataSize / M10) / (elapsedTime / K10);
final int eta = (int)(((totalDataSize - processedDataSize) / M10) / speed);
... // and update the statistics object
}
private void updatePresentation (final @ListensTo RefreshPresentationMessage message)
{
presentation.updateStatistics(statistics);
if (refreshing)
{
new RefreshPresentationMessage().sendLater(1, TimeUnit.SECONDS);
}
}
}
Actually another advantage of message-based designs is that a user interface can be easily updated without having to know a large number of listeners.
Activation
Actors are managed objects and must be never directly accessed. To accomplish this, they are declared by means of activators, which typically are grouped together such as in:
package it.tidalwave.integritychecker.impl;
import org.openide.util.lookup.ServiceProvider;
import it.tidalwave.actor.spi.ActorGroupActivator;
import static it.tidalwave.actor.spi.ActorActivator.*;
@ServiceProvider(service=IntegrityCheckerActivator.class)
public class IntegrityCheckerActivator extends ActorGroupActivator
{
public IntegrityCheckerActivator()
{
add(activatorFor(FileObjectDiscoveryActor.class).withPoolSize(8));
add(activatorFor(FileLoaderActor.class).withPoolSize(1));
add(activatorFor(FingerprintComputerActor.class).withPoolSize(4));
add(activatorFor(PersistenceManagerActor.class).withPoolSize(1));
}
}
Activators specify the pool size of each actor. Given that, it's possible to activate and deactivate the group:
Locator.find(IntegrityCheckerActivator.class).activate();
...
Locator.find(IntegrityCheckerActivator.class).deactivate();
For people not used to the NetBeans Platform, @ServiceProvider is a compile-time annotations that
generates a service declaration into META-INF/services, while Locator is a facility
that retrieves the reference at runtime.
Actors can have methods annotated with @PostConstruct and @PreDestroy, which will be
called just before activation and just after deactivation, of course in a thread-safe way. There's the guarantee
that messages can't be delivered before activation is completed and after deactivation.
Simpler than Akka... for how long?
This works, I enjoy the fact that I can avoid synchronized blocks and so far I don't miss the fact that that thing is clearly much less performant than Akka. Everything fits into less than 40k of jar file and it's much simpler than Akka (whose complexity is justified by the fact that it offers many more features). So what? Distributing to a network is something that we can't ignore in a cloud oriented world. So it's likely that going on I'll see the need for more features: often you discover that you need new features as you go on. Smell of reinventing the wheel ahead!
For instance, consider the FileLoadActor. I've previously said that experimental evidence
demonstrates that it makes sense (at least with large files) to have it instantiated in a single instance, thus
serializing data access to the disk. This makes sense given the physical nature of a magnetic disk. But this
happens with a single disk: if you have more than one, it probably makes sense to have one instance per disk.
Having a Solid State Drive (SSD) changes the rules. This means that you must have some more complex way to
dispatch messages, a form of routing. Akka offers it, and it would be unwise to rewrite this feature from scratch.
So now I'm going to start phase two, that is to reimplement this stuff upon Akka (using the 2.0 milestone that's already available). In a few weeks I'll let you know how the story goes on.
The code that I described in this blog post are available at the Mercurial repository http://bitbucket.org/tidalwave/solidblue-src, tag 1.0-ALPHA-4.
In a further post I'll talk about how Collaborations are used by blueShades, which features more complex interactions with the user. See you later.